Awesome-Meta-Learning
Zero-Shot / One-shot / Few-Show / Low-Shot Learning
Siamese Neural Network是一种Metric Learning的方法,适用于类别数量特别多或者类别数量不确定的情况。当类别的样本数量过少时,传统方法难以学到较好的效果,故使用Siamese Neural Network去学习一个相似性度量,如欧氏距离、cosine距离等。训练时最小化来自相同类别的一对样本的损失,最大化来自不同类别的一对样本的损失。用这个度量去比较和匹配新的未知类别的样本。
在Few-Shot情况下,Prototypical Network对每个类别的样本做embedding后对结果求均值,作为该类别的prototype。在对新样本做预测的时候,新样本的embedding结果距离哪个prototype最近就将该样本分到此类别。在Zero-Shot情况下,meta-data向量不是由训练集的support样本产生的,而是根据每个类的属性描述、原始数据等生成的。如下图: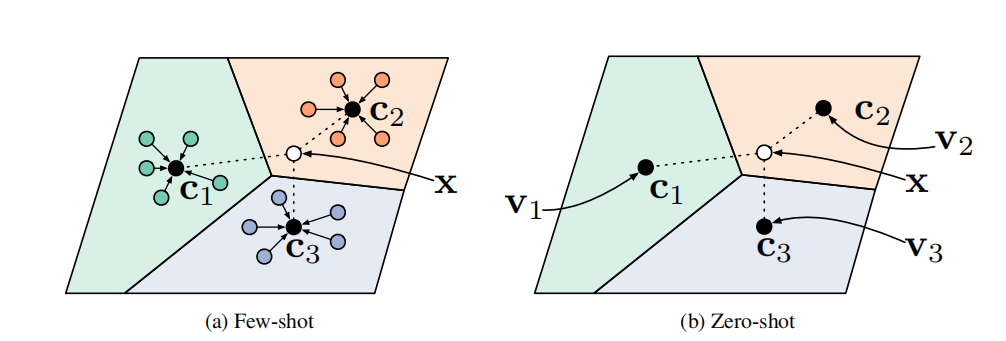
融合了参数化和非参数化的方法,训练时将样本作为序列输入LSTM,让模型纵观所有的样本并进行输出。测试时用LSTM对测试样本进行K此迭代编码进行输出。使用Cosine距离对两者的相似度进行度量,随后做softmax。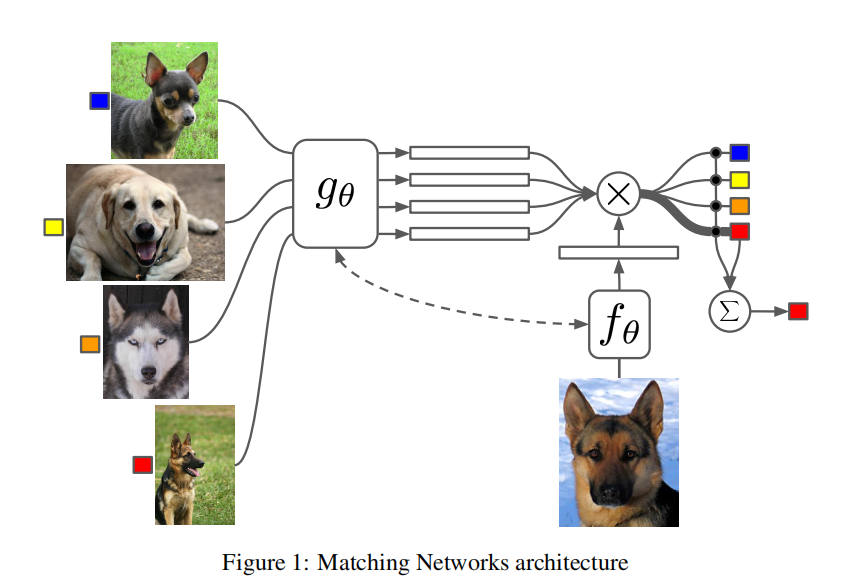
Learning to Compare: Relation Network for Few-Shot Learning, (2017), Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip H.S. Torr, Timothy M. Hospedales.
One-shot Learning with Memory-Augmented Neural Networks, (2016), Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, Timothy Lillicrap.
Optimization as a Model for Few-Shot Learning, (2016), Sachin Ravi and Hugo Larochelle.
An embarrassingly simple approach to zero-shot learning, (2015), B Romera-Paredes, Philip H. S. Torr.
Low-shot Learning by Shrinking and Hallucinating Features, (2017), Bharath Hariharan, Ross Girshick.
Low-shot learning with large-scale diffusion, (2018), Matthijs Douze, Arthur Szlam, Bharath Hariharan, Hervé Jégou.
Low-Shot Learning with Imprinted Weights, (2018), Hang Qi, Matthew Brown, David G. Lowe.
One-Shot Video Object Segmentation, (2017), S. Caelles and K.K. Maninis and J. Pont-Tuset and L. Leal-Taixe’ and D. Cremers and L. Van Gool.
One-Shot Video Object Segmentation, (2017), S. Caelles and K.K. Maninis and J. Pont-Tuset and L. Leal-Taixe’ and D. Cremers and L. Van Gool.
One-Shot Learning for Semantic Segmentation, (2017), Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, Byron Boots.
Few-Shot Segmentation Propagation with Guided Networks, (2018), Kate Rakelly, Evan Shelhamer, Trevor Darrell, Alexei A. Efros, Sergey Levine.
Few-Shot Semantic Segmentation with Prototype Learning, (2018), Nanqing Dong and Eric P. Xing.
Dynamic Few-Shot Visual Learning without Forgetting, (2018), Spyros Gidaris, Nikos Komodakis.
Feature Generating Networks for Zero-Shot Learning, (2017), Yongqin Xian, Tobias Lorenz, Bernt Schiele, Zeynep Akata.
Meta-Learning Deep Visual Words for Fast Video Object Segmentation, (2019), Harkirat Singh Behl, Mohammad Najafi, Anurag Arnab, Philip H.S. Torr.
Model Agnostic Meta Learning
与模型无关的元学习方案,可以与采用梯度下降方法更新参数的算法相结合,而不改变参数的数量。如图所示,MAML的目标是学习一个$\theta$,使得其在新任务上只经过一次或几次梯度下降就可以达到较好的结果。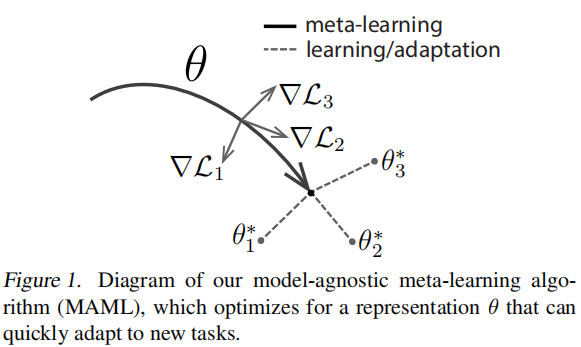
故MAML的损失函数为在support-set上进行一次梯度下降后,在query-set上的损失。由于计算梯度的时候要计算二阶导数,故也可舍弃一定的performance采用一阶近似。
Adversarial Meta-Learning, (2018), Chengxiang Yin, Jian Tang, Zhiyuan Xu, Yanzhi Wang.
On First-Order Meta-Learning Algorithms, (2018), Alex Nichol, Joshua Achiam, John Schulman.
Meta-SGD: Learning to Learn Quickly for Few-Shot Learning, (2017), Zhenguo Li, Fengwei Zhou, Fei Chen, Hang Li.
Gradient Agreement as an Optimization Objective for Meta-Learning, (2018), Amir Erfan Eshratifar, David Eigen, Massoud Pedram.
A Simple Neural Attentive Meta-Learner, (2018), Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, Pieter Abbeel.
Personalizing Dialogue Agents via Meta-Learning, (2019), Zhaojiang Lin, Andrea Madotto, Chien-Sheng Wu, Pascale Fung.
How to train your MAML, (2019), Antreas Antoniou, Harrison Edwards, Amos Storkey.
Libraries
Datasets
Reference:
Awesome-Meta-Learning