
深度学习
回顾机器学习
定义
一个计算机程序,针对某个特定任务,从历史数据学习,并且越做越好。
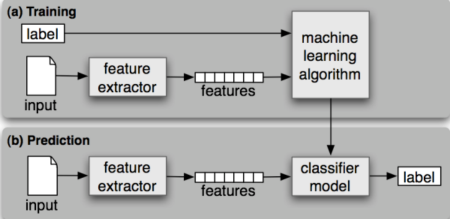
机器学习的核心
- 数据
- 模型
分类
- 有监督学习
- 回归
- 线性回归
- 分类
- SVM
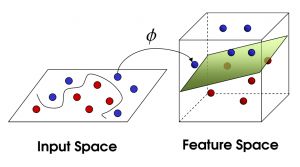
- SVM
- 回归
- 无监督学习
- 聚类
- 主成分分析
- 半监督学习
- 增强学习(Reinforcement Learning)
学习过程(监督学习)
- 损失函数(loss function)
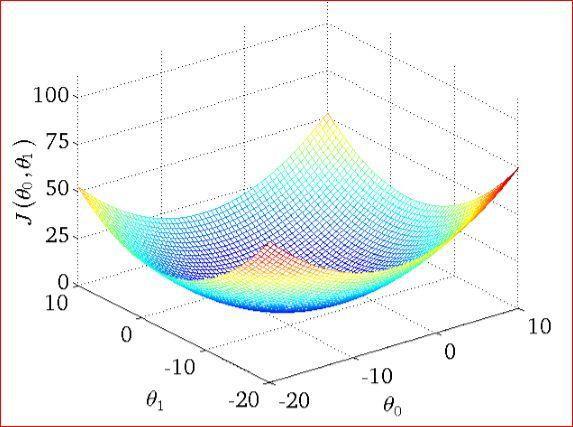
- 优化方法
- 梯度下降
深度学习是什么
wiki:深度学习(英语:Deep Learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。
深度学习和传统机器学习算法的异同
数据方面
Andrew Ng:“与深度学习类似的是,火箭发动机是深度学习模型,燃料是我们可以提供给这些算法的海量数据。
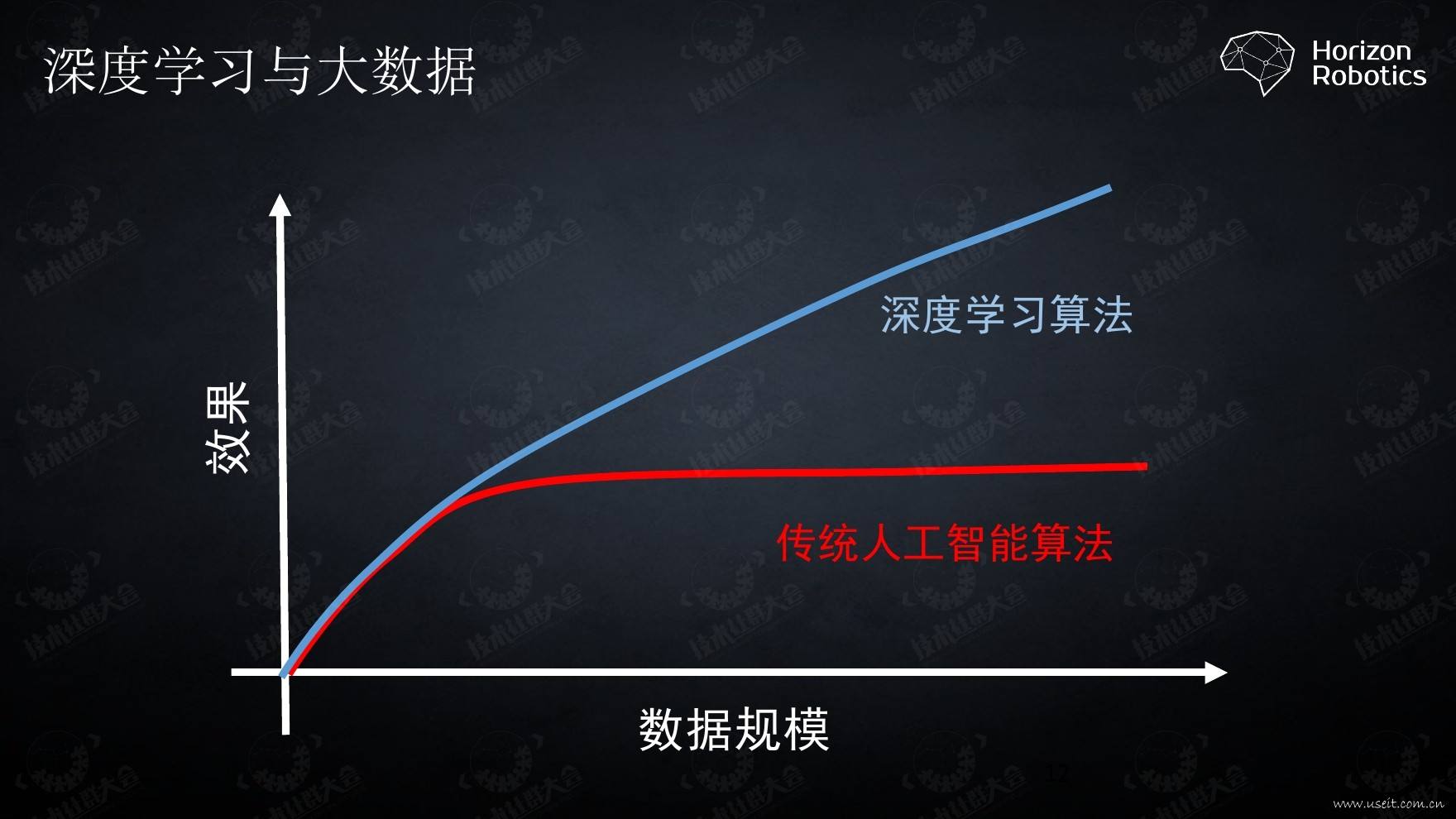
计算量方面
深度学习在更新模型网络权重时涉及大量矩阵运算,在CPU上跑速度会很慢,而传统机器学习算法随便一台电脑就可以跑。因此深度学习最好在GPU上跑。
耗时量级:
- 传统机器学习:秒、分钟、小时
- 深度学习:小时、天、周
输入特征方面
机器学习依赖于人类精心设计的特征才能取得较好的结果,深度学习主张让算法自己从原始数据中发现特征。不用太过高深的先验知识做支撑,但因此对数据量的需求比较大。
深度学习算法
人工神经网络(ANN)
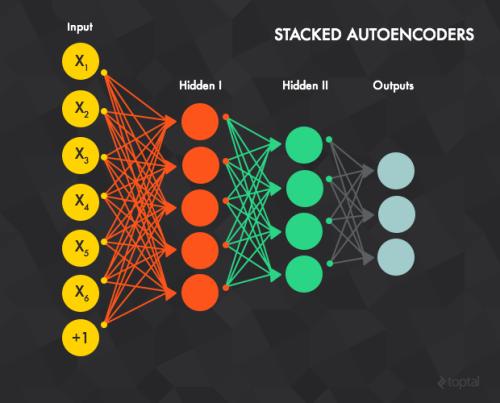
其中的一个节点: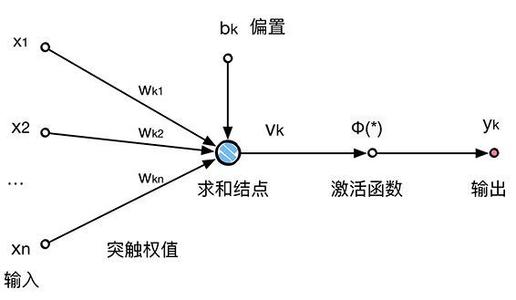
激活函数一定是一个非线性函数,用来增加网络的复杂性。不然不管网络有多少层,始终是一个线性函数。
常用激活函数:
- relu
- x if x > 0
- 0 if x <= 0
- tanh
卷积神经网络(CNN)
卷积
在深度学习里的卷积,与数学上的和信号处理上关于卷积的概念有些不同.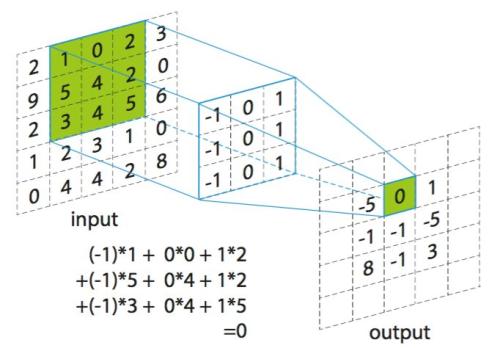
CNN结构
两条基本假设:
- 最底层特征都是局部性的,也就是说,我们用10x10这样大小的过滤器就能表示边缘等底层特征
- 图像上不同位置处特征是类似的,也就是说,我们能用同样的一组分类器来描述不同位置的图像——平移不变性
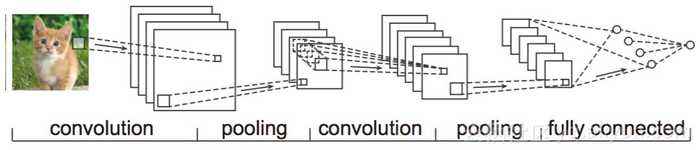
关键:局部连接,权值共享,池化
CNN在处理图像数据时与ANN相比有着巨大的优势,通过局部连接、权值共享和池化大大减少了参数的数量,从而大大减少计算量、减少过拟合并大大提高模型的表现。
模型训练
模型训练的过程可以认为是使损失函数最小化的过程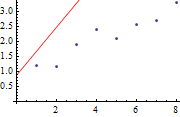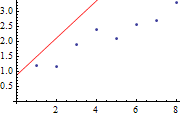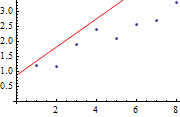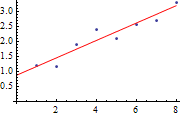
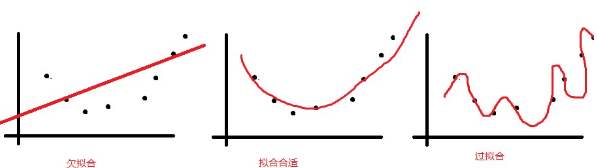
模型泛化与过拟合、欠拟合问题
因为深度学习的表达能力很强,当你的模型的表现很好时,你需要警惕,是模型学到了规律还是说模型记住了数据。检测方法也很简单,前者在一个陌生的数据集上表现依然很好,而后者反之。因此,在设计模型的时候也要考虑使用一些方式来尽可能的避免过拟合,从而得到较好的泛化能力。
书籍推荐
入门书籍:
该书简单易懂,为keras之父写的书。好上手,学了就能用,里面有很多demo可以跑。
进阶书籍:
该书讲了很多数学、线代、概率论还有优化的东西,被奉为深度学习圣经,俗称“花书”,适合作为工具书,在手边随时查阅,入门较吃力。
主流深度学习框架
- Tensorflow
- Pytorch
- Keras
- Paddlepaddle
总结
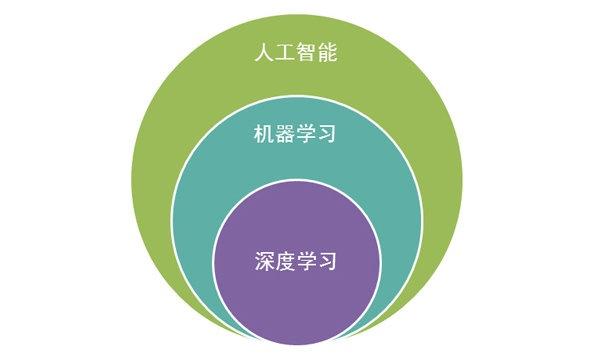
- 人工智能>机器学习>深度学习
- 需要更多的数据量和算力
- ANN
- 输出是输入的复杂非线性函数
- CNN
- 局部连接
- 权值共享
- 池化
- 模型训练
- 损失函数
- 梯度下降
- 注意过拟合与欠拟合