机器学习概览
机器学习是什么
定义
wiki:机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
Arthur samuel:机器学习是在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
一个计算机程序,针对某个特定任务,从历史数据学习,并且越做越好。
让我引用一张图片来说明: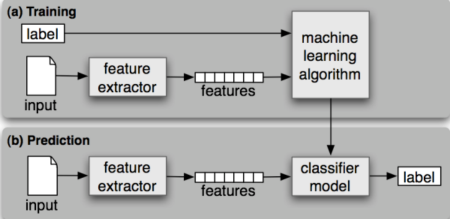
注意:这里是用有监督模型举例(后面会对这个名词进一步解释)
针对机器学习最重要的内容
- 数据:经验只有转化为了计算机能够理解的数据,才能让计算机从中学习。谁的数据量大、质量高,谁就占据了机器学习和人工只能领域最有利的资本。
- 模型:即算法,有了数据之后,可以设计模型,通过数据来训练这个模型。这个模型就是机器学习的核心,作为用来产生决策的中枢。
数据的分类
- 结构化数据———储存在数据库中的数据
- 非结构化数据——-语音信号、图像图形、自然语言
机器学习能干什么
- 语音识别、机器翻译(微软Cortana、苹果Siri、科大讯飞、谷歌翻译)
- 人脸识别(微信、支付宝、宿舍门禁)
- 量化交易(预测股市)
- 房价预测
- 推荐系统(淘宝、京东、抖音)
- 医生/老中医
- 解微分方程、不定积分(见:AI拿下高数一血,求解微分方程、不定积分只需1秒,成绩远超Matlab)
- 寻找淹没在背景噪声中的小信号(Higgs Boson Machine Learning Challenge、引力波信号、引力透镜参数预测)
好用的机器学习库以及书籍推荐
scikit-learn:最有名且易用好上手,广泛作为机器学习的入门库(Python)
书籍:
机器学习的分类
按照模型的学习方式,我们可以分为如下几类:
有监督学习
对于数据集中的每一条数据,我们在把它交给算法前就有了相应的“正确答案”,我们的算法就是在基于这些我们人为给定的“正确答案”在做预测。
有监督学习的任务一般是回归或者分类问题:
- 回归:线性回归
比如通过商品房的地段、高度、外形、面积、采光面积等参数来预测商品房价格。预测结果是一个连续的值。 - 分类:支持向量机(SVM)、决策树、逻辑回归、朴素贝叶斯、KNN
比如通过西瓜的颜色、大小、重量、花纹等等预测西瓜甜不甜。
请注意,这里我们预测的输出只包括甜和不甜,是一个离散值,这是一个二分类的问题。
反之,若是我们输出的是西瓜介于0到1之间的的甜度(0是一点都不甜,1是超级甜),那这个分类问题就转化为了回归问题。
无监督学习
对于数据集中的所有数据,他们没有一个相应的“正确答案”。算法要做的是利用算法自动的将数据归类,也叫做聚类。
- KMEAN
半监督学习
介于监督学习和无监督学习之间的一种方式。即一部分数据有标记,一部分数据没有标记。
增强学习
增强学习是一种有反馈的学习方式。
例子:贪吃蛇问题
一个N×N的格子里,定义贪吃蛇每一步上下左右随机行走,碰到墙或者自身则得到负反馈,吃到果子得到正反馈,在训练很多轮以后,贪吃蛇就学会了如何躲避墙和自身去吃果子。
机器学习的一般步骤
数据采集和标记
- 构建数据集:收集尽可能的多的特征,给出数据标记(人工或自动)
预测房价:面积大小、房间数、地段、楼龄等;
芝麻信用:海量的用户交易数据;
数据清洗
- 对数据中的单位进行统一
- 去掉重复数据、噪声和数据缺失
特征选择
- 从哪些特征对进行机器学习是有用的;人工设计或自动选择
模型选择
- 根据问题选择模型,聚类还是分类,回归还是分类
模型训练和测试
- 把数据集合分为训练集和测试集,用训练集训练模型,训练完成后用测试集测试模型的精度。(测试集必须是模型没有见过的数据)
模型性能评估与优化
- 训练时长,训练数据是否足够,是否能满足需要
模型使用
- 训练好的模型进行存储,以备下次使用
机器如何学习
损失函数
例如:
用一维线性回归举例:
$$ y = kx+b $$
x就是我们的input,y就是我们的label,我们首先给算法一定的(x,y)数据,算法拟合出来一条直线方程,当我们再输入x数据时,模型能够预测出相应的y。这就是一个简单的有监督机器学习例子。但是,机器怎么知道哪个k和b是最好的呢?
也就是说,我们需要用一个指标来衡量模型和数据的拟合程度,而模型的预测值和真实值的差,我们叫做损失函数。在这里,我们训练的一个线性回归模型,可以是让MSE(均方误差)最小,MSE在这里被称为这个回归模型的损失函数,它代表了预测值与真实值的偏离程度。而我们机器学习的过程就是通过改变k和b使得损失函数取得最小值。
$$
L_{MSE}(\hat{y}, y)=\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-\hat{y}_{i}\right)^{2}
$$
这里的m表示数据个数。
除此之外,对于二分类问题来说,常用的损失函数是二元交叉熵损失(Logistic损失):
$$
L_{\text {logistic }}(\hat{y}, y)=\frac{1}{m} \sum_{i=1}^{m}[-y_{i} \log \hat{y}{i}-\left(1-y{i}\right) \log \left(1-\hat{y}_{i}\right)]
$$
这里的 $\hat{y}$ 代表预测y=1的概率。
梯度下降
我们知道了我们的目标是让k和b最小,那我们怎么实现呢?接下来我们来看一下它的解决方案——使用梯度下降算法来更新参数。
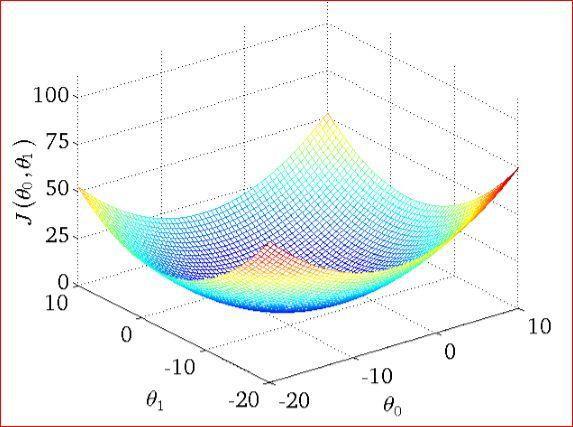
这里 $\theta_0$ 和 $\theta_1$ 分别代表k和b。
我们从一个随机的k和b出发,沿着向下最快的路径行走,直到达到最低点,即此时k和b收敛于一个定值,这个定值就是我们想要得到的使得损失函数最小的值。
代码实现
本文使用scikit-learn实现一个线性回归模型举例:
1 | from sklearn.linear_model import LinearRegression #从sklearn引入线性回归模型 |
常用的API有:
| API | 解释 |
|---|---|
| fit(X_train,Y_train) | 训练模型 |
| predict(X_test) | 预测测试数据的结果 |
| score(X_test,Y_test) | 测试预测数据的score(例如正确率) |
这里只是展示了很少很少的API,还有很多非常非常实用的API及教程参见官方文档
总结
- 1.获取数据
- 2.处理数据(80%的时间)
- 3.训练模型(20%的时间)
- 4.进行预测
- 5.观察结果,不满意则重复2.3.4.步,满意则保存模型